


AIR’s Data Services Team is dedicated to cleansing and/or converting exposure data for clients, running that data through our catastrophe models, and helping them understand the results. As mentioned in a previous blog, this allows clients to achieve increased efficiency and streamline their workflows, which in turn frees resources to focus on their organization’s core competencies and objectives.
Improving Data Services through Machine Learning
A central part of AIR’s Data Services workflow is dedicated to the cleansing of property/exposure data into a format that can be consumed by Sequel’s Impact exposure management product and AIR’s loss modeling platforms—Touchstone® and Touchstone Re™. This involves the painstaking assessment and categorization of (often ambiguous) exposure descriptions into AIR’s standard exposure data format (which is open source and freely available).
When performed manually, this is an extremely resource-intensive and time-consuming process. Therefore, we developed a machine learning (ML) algorithm that takes advantage of the wealth of data available to AIR to automate this process in an efficient and robust way.
Given AIR’s privileged position as a Verisk business, we joined forces with the Verisk Innovative Analytics (VIA) group, whose main objective is the creation of new information and products from available data. Together, we developed an ML-based solution that both dramatically accelerates the Data Services workflow and provides clients with several operational benefits.
As shown in Figure 1, the primary output of the ML-based algorithm is a recommendation as to the most appropriate categorization of the “raw” exposure input data. This is done in a consistent way because the algorithm will always recommend the same categories for the same input data.
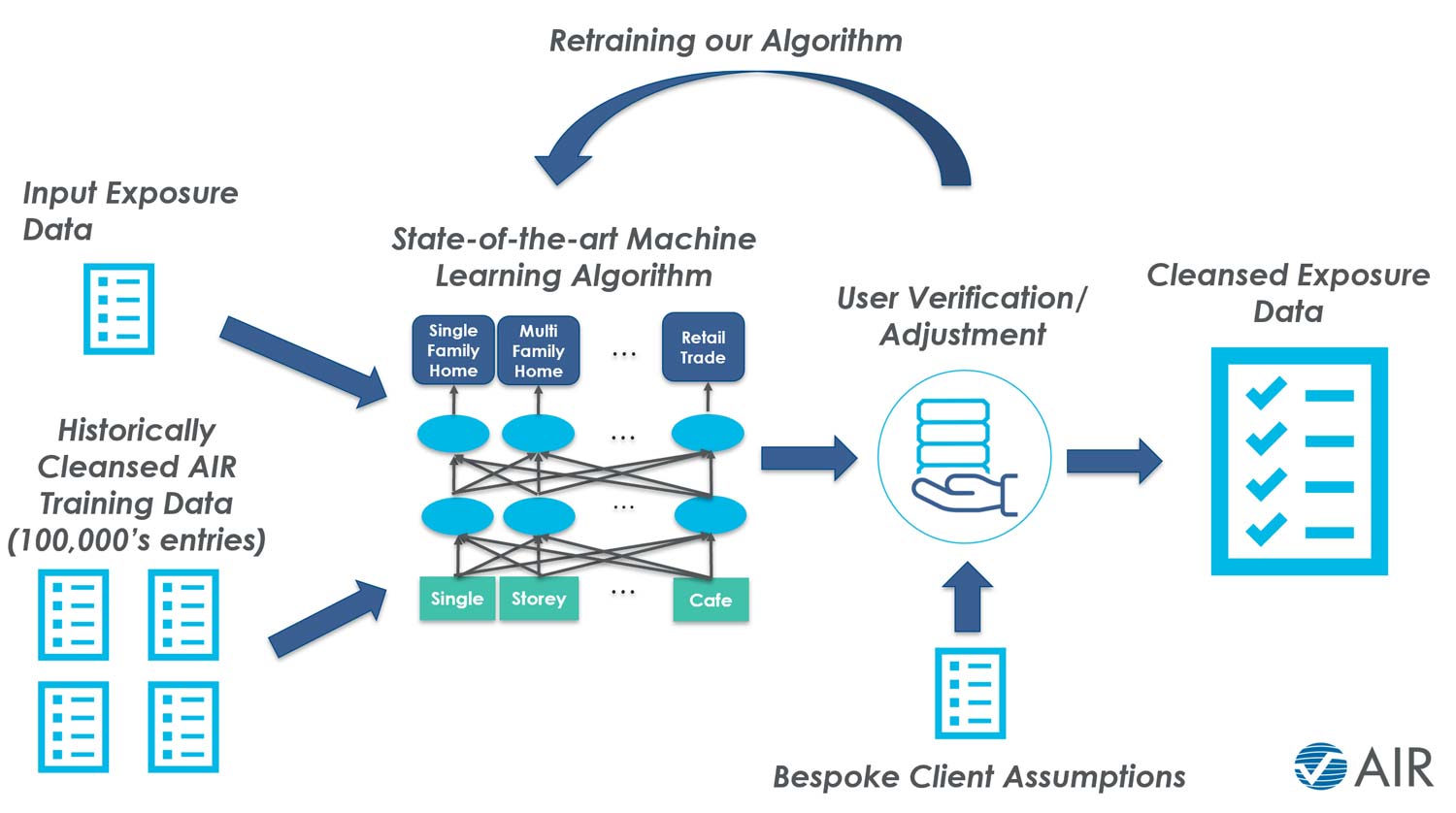
The framework is designed so that the user stays in control. AIR’s Data Services expertise is extremely valuable for ensuring appropriate matches and continuing to train the algorithm. The final stage of the tool’s application taps into the user’s knowledge of property data whereby they confirm or adjust the ML output as necessary.
This framework also allows for client-specific bespoke modeling assumptions to be defined and used to overrule the algorithm’s recommendation for specific input exposure descriptions. Notably, any adjustment made by the user is fed back into the model such that it “learns” from every iteration. This allows a continued improvement in both accuracy and turnaround times, as the increased accuracy inevitably leads to less and less need for user adjustments.
The value added to clients is evident. This solution not only minimizes human error and variability potentially associated with a manual categorization process, but also allows for increased accuracy and consistency—simultaneously reducing processing times by up to 35%.
If you want to know more about how you can benefit from AIR’s AIR Data Services, reach out to our team at LondonDS@air-worldwide.com.



